
As the scope of Artificial Intelligence (AI) and machine learning expands, the significance of data protection in AI tools is becoming increasingly important.
With the increasing trend of personalization in AI, privacy laws, and regulations such as the General Data Protection Regulation (GDPR), are placing a stronger emphasis on the privatization of data and data anonymization.
This post will provide a comprehensive guide to understanding these key concepts, their significance in AI technology, and how to effectively implement them.

Understanding Key Concepts
Definition of Data Privatization
Data privatization is a critical concept in today’s digital age, as it addresses the fundamental need to safeguard individuals’ personal and sensitive information.
Beyond just encryption and secure AI practices, it encompasses a comprehensive approach to data protection.
This includes stringent access controls, robust authentication mechanisms, and adherence to data processing regulations.
By emphasizing that only authorized entities can access, manage, and utilize data, data privatization promotes trust among users and organizations.
Ensuring that personal information is handled responsibly and ethically, ultimately enhancing data security and privacy for individuals and businesses alike.
Definition of Data Anonymization
Data anonymization is a crucial technique in the realm of data privacy and security. It involves transforming data in a way that makes it nearly impossible to link it back to specific individuals while still retaining its utility for analysis and research.
By obscuring or replacing identifiable information, such as names or social security numbers, with pseudonyms or tokens, data anonymization allows organizations to share valuable datasets for research, analytics, or collaboration.
Without violating privacy regulations or exposing individuals to potential risks of re-identification.
This balance between data utility and privacy protection is essential in today’s data-driven world, where responsible data management is a top priority.
Learn more about data privacy on this video :
The Importance of Data Privacy in AI Tools
Data privacy is undeniably a critical aspect of AI and privacy, given that AI tools frequently have access to an extensive repository of personal data. This wealth of information makes data security an utmost priority.
Ensuring data privacy within the realm of machine learning and AI is not solely a matter of compliance with regulations; it’s about safeguarding individuals’ sensitive information.
One of the primary concerns in this context is the potential for data breaches. A breach occurs when unauthorized individuals gain access to and exploit sensitive data.
Such incidents can have profound repercussions, ranging from financial losses to reputational damage and even legal consequences.
Therefore, robust data privacy measures are essential to prevent data breaches and their associated fallout.
By implementing stringent data privacy and anonymization practices, AI developers can protect users’ personal information from unauthorized access and misuse. This, in turn, helps to build trust with users, fostering a sense of security and confidence in the technology.
When users trust that their data is safe, they are more likely to engage with AI tools, share information, and interact more openly, leading to a more successful and harmonious AI-user relationship.
The Role of Data Anonymization in AI Tools
Data anonymization plays a crucial role in maintaining privacy while personalizing AI and enabling responsible data sharing and data use.
By anonymizing data, AI tools can utilize the wealth of information available in big data without compromising user privacy.
This is especially important in AI data handling, where the responsible use of personal data can greatly enhance the user experience if managed correctly.
How to Achieve Data Privatization in AI Tools
Step-by-step Guide to Data Privatization
Achieving data privatization in AI tools is a multifaceted process that demands a comprehensive approach. It begins with data encryption, securing data during transit and storage, and enforcing access controls to ensure only authorized personnel can access it.
However, these initial steps are just the foundation of a robust data privacy framework.
Data anonymization is a crucial element, involving the transformation or removal of personally identifiable information (PII) to protect individual privacy while maintaining data utility for AI applications.
Establishing a clear data retention policy is essential to minimize data exposure and reduce the risk of data breaches. This policy outlines how long data will be retained and when it will be securely disposed of, ensuring responsible data management.
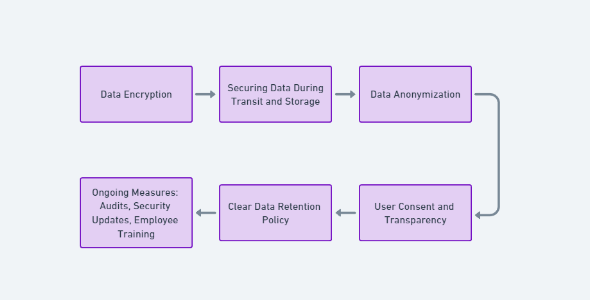
User consent and transparency are vital components of data privatization. AI developers should obtain informed consent from users regarding data collection and usage. While transparently communicating how data will be used and stored.
Ongoing measures include regular audits, security updates, and employee training programs to adapt to evolving threats, monitor the effectiveness of data protection measures, and maintain a culture of data privacy within the organization.
These collective efforts are integral to achieving robust data privatization in AI tools and ensuring the responsible handling of data in an increasingly data-driven world.
Best Practices in Data Privatization
Incorporating a “privacy by design” approach into AI tool development signifies a proactive commitment to data privacy. This approach necessitates that privacy considerations are integrated seamlessly from the outset, encompassing every phase of the AI tool’s lifecycle.
This includes not only the initial design and development but also ongoing monitoring, updates, and assessments of potential privacy risks.
By embedding privacy at the core of the AI design process, companies can minimize the likelihood of privacy breaches. And ensure that data privacy remains a fundamental principle throughout the tool’s evolution.

Furthermore, transparency with users is paramount in building trust. Companies should clearly communicate how user data is collected, processed, and stored.
This transparency fosters a sense of control and understanding among users, allowing them to make informed decisions about sharing their data.
Open and honest communication regarding data practices enhances user confidence and can ultimately lead to greater user engagement and satisfaction.
Additionally, staying informed about evolving privacy laws and regulations is essential in this ever-changing landscape to adapt and ensure ongoing compliance, demonstrating a commitment to upholding data privacy standards and respecting users’ rights.
Implementing Data Anonymization in AI Tools
The Process of Data Anonymization
Data anonymization is a multistep process designed to ensure data privacy while addressing privacy concerns. Initially, data is collected with user consent, adhering to ethical and legal guidelines.
Following data collection, identifiable information, such as names and addresses, is either removed or transformed using various anonymization techniques like data masking, pseudonymization, and generalization.
These methods aim to make it challenging to trace the anonymized data back to specific individuals, while preserving data utility for analysis and research.
Throughout the process, privacy concerns are paramount. Striking a balance between utility and privacy protection is critical. Over-anonymizing data can render it useless for analysis, while insufficient anonymization can expose individuals to privacy breaches and re-identification risks.
Rigorous testing of the anonymized data is vital to ensure that even advanced data linkage techniques cannot re-identify the original data, thus maintaining a high level of privacy assurance.
In today’s data-centric landscape, responsible data anonymization is essential for safeguarding individuals’ privacy while extracting valuable insights from collected data.
Best Tools and Techniques for Data Anonymization
- Data anonymization, such as CloverDX, is a fundamental practice in data privacy, employing common techniques such as data masking, pseudonymization, and generalization.
- Data masking, such as Delphix Masking, involves substituting identifiable data with fictional yet realistic information, preserving dataset utility while concealing individual identities.
- Pseudonymization, such as Orion, replaces identifiable data with artificial identifiers or tokens, allowing for data linkage and analysis without exposing personal details, making it valuable in healthcare and other contexts.
- Generalization, in contrast, transforms specific data attributes into broader categories, reducing data granularity and minimizing the risk of identifying individuals.
These anonymization methods strike a balance between data utility and privacy, essential in AI development and deployment.
By implementing these techniques, organizations can harness the power of data-driven insights while safeguarding sensitive information and adhering to stringent privacy regulations.
By doing so, ensuring responsible data sharing and use in the ever-evolving landscape of AI technology.
Challenges and Solutions in Implementing Data Privacy and Anonymization
Challenges
Data privacy and anonymization present several challenges, especially as organizations strive to leverage big data while complying with increasing regulatory requirements and maintaining public trust.
Balancing Data Utility with Privacy:
- Ensuring anonymized data remains useful for analysis while effectively obscuring individual identities.
Compliance with Evolving Regulations:
- Keeping up-to-date with and adhering to privacy laws and regulations like GDPR and CCPA.
Data Re-Identification Risks:
- Preventing the risk where anonymized data can be traced back to individuals using advanced techniques or by combining datasets.
Complexity of Data Anonymization Techniques:
- Implementing sophisticated anonymization techniques that require deep technical expertise, such as differential privacy and homomorphic encryption.
Cost and Resource Allocation:
- Allocating sufficient resources and budget to implement and maintain effective data privacy and anonymization programs.
Public Perception and Trust:
- Building and maintaining public trust by demonstrating commitment to privacy and ethical data use.
Solutions
With increasing regulations and growing consumer awareness, businesses must adopt robust solutions for data privatization and anonymization. These measures not only safeguard sensitive information but also foster trust and compliance.
Implement Differential Privacy:
- Add random noise to data or use statistical techniques to ensure individual data points cannot be traced back to the original data subjects, while still allowing for meaningful aggregate data analysis.
Use Federated Learning:
- Process data locally on user devices and only share model updates or insights, not the raw data itself, with the central server or cloud. This minimizes the risk of data exposure and enhances privacy.
Apply Homomorphic Encryption:
- Encrypt data in such a way that it can still be processed or analyzed without being decrypted. This allows for data to be used in computations securely without exposing the underlying information.
Data Masking and Tokenization:
- Replace sensitive data elements with non-sensitive equivalents, known as tokens, which can be mapped back to the original data through a secure tokenization system, or mask data to hide personal identifiers.
Data Minimization:
- Collect only the data that is strictly necessary for the intended purpose, and avoid storing excessive information that could increase privacy risks. This also includes deleting data that is no longer needed.
Regular Privacy Audits and Impact Assessments:
- Conduct regular assessments to identify and mitigate privacy risks associated with data processing activities. This includes reviewing data collection, storage, and processing practices to ensure compliance with privacy laws and regulations.
The Future of Data Privacy and Anonymization in AI Tools
As AI technology advances, it brings forth evolving approaches to data privacy and anonymization, with a heightened focus on individual privacy.
Quantum computing’s emergence holds the promise of unbreakable encryption. Which could bolster data protection and safeguard individual privacy to an unprecedented extent.
Moreover, evolving regulations, such as the General Data Protection Regulation (GDPR) and its global counterparts, continue to shape the landscape of data in machine learning and AI through data protection laws.
These regulations underscore individuals’ rights to control their personal data and necessitate robust protection measures.

Thus, AI developers and data practitioners must remain vigilant, ensuring that their AI systems not only comply with existing regulations. But also prioritize individual privacy throughout the data lifecycle.
In this dynamic environment, the challenge lies in striking a delicate balance between reaping the potential benefits of AI and preserving individual privacy rights.
Adapting and innovating in data usage and anonymization techniques will be essential to meet the evolving demands of the digital age. While safeguarding the privacy and security of individuals’ data.
Conclusion
Implementing effective data privatization and anonymization practices in AI tools is a complex task that requires a deep understanding of both AI technology and privacy laws.
However, with the right strategies and techniques, companies can successfully balance the need for data utility with the imperative of user privacy.
This not only ensures compliance with privacy regulations but also builds trust with users, enhancing the overall user experience.
Looking to develop the right AI Solution to protect your data and your customer’s privacy? Contact our experts at iterates.